flowchart LR
A(离线实验) --> B(小流量A/B测试)
B --> C(全流量A/B测试)
1 短期消费侧指标
- 点击率:=点击次数/曝光次数
- 点赞率:=点赞次数/点击次数
- 收藏率:=收藏次数/点击次数
- 转发率:=转发次数/点击次数
- 阅读完成率:=滑动到底次数/点击次数 \(\times\) f(笔记长度)
| 用户规模 | 消费 | 发布 |
|---|---|---|
|
|
|
2 实验流程
- 离线实验
-
收集历史数据,在历史数据上做训练、测试、算法没有部署到产品中,没有跟用户交互,离线实验不如线上实验可靠
- 小流量A/B测试
-
把算法部署到实际产品中,用户实际跟算法做交互。
3 推荐系统的链路
flowchart LR
A[(几亿物品)] --> B((召回))
B --> |几千物品| C((粗排))
subgraph 排序
C
D
end
C --> |几百物品| D((精排))
D --> |几百物品| E((重排))
E --> |几十物品| 完成
- 粗排
-
较小的机器学习模型
- 精排
-
较复杂的神经网络
- 召回通道
-
协同过滤、双塔模型、关注的作者等
flowchart LR
A[(几亿物品)] --> |召回通道1| B[(几百)]
A --> |召回通道2| C[(几百)]
A --> |...| D[(几百)]
A --> |召回通道10| E[(几百)]
B & C & D & E --> F{粗排,精排}
F --> G[(几百)]
G --> H{重排}
H --> H1((物品1))
H --> H2((物品2))
H --> H3((...))
H --> H4((物品80))
3.1 粗排、精排
flowchart LR
a_1[用户特征] --> b{神经网络}
a_2[物品特征] --> b
a_3[统计特征] --> b
b --> |预测| d[点击率]
d --> 排序分数
3.2 重排
- 做多样性抽样(MMR,DDP)从几百篇中选出几十篇
- 用规则打散相似笔记
- 插入广告、运营推广内容并根据生产要求调整排序
4 AB测试
召回实验实现了一种GNN召回通道,离线实验结果正向,下一步做线上小流量A/B测试,考察新的召回通道对线上指标的影响。模型中有一些参数,比如GNN的深度取值 \({1,2,3}\) 需要用A/B测试选取最优参数。
4.1 随机分桶
全部n位用户分成b个桶:
- 首先用
哈希函数把用户ID映射成某个区间内的整数,然后把这些整数均匀分成b个桶; - 计算每个桶的业务指标比如DAU、人均使用推荐的时长、点击率,如果某个实验组指标显著优于对照组,则说明对于的策略有效,值得推全。
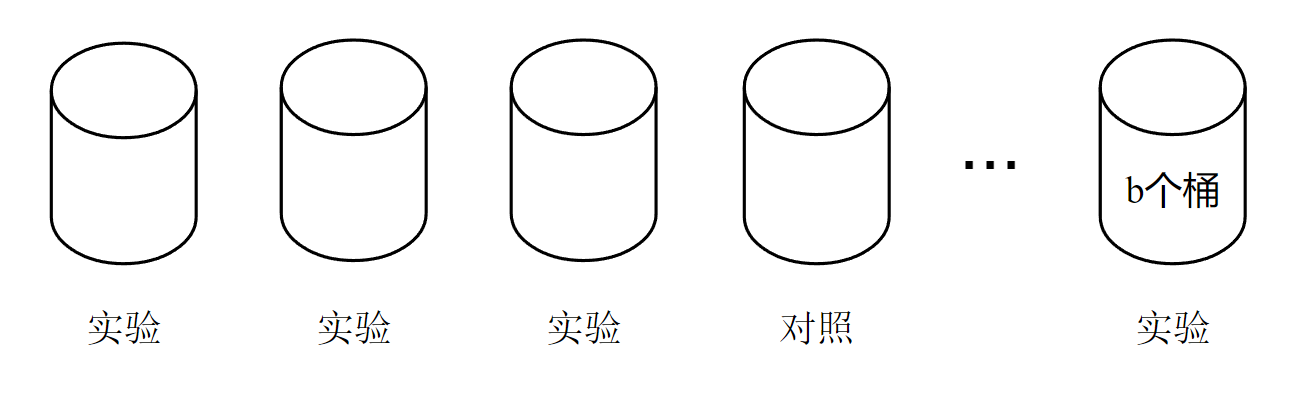
4.2 分层实验
各部门都需要做A/B测试,随机分成b个桶后,最后只能同时做b-1组实验:
- 分层实验:指召回、粗排、精排、重排、用户界面、广告这些层。
- 同层互斥:同召回层的多个实验不得在同一个桶内进行,防止一个桶同时被两个召回实验影响。
- 不同层互斥:每一层独立随机对用户做分桶。每一层都可以独立用全部的用户做实验
召回层分成 \(u_1,\ldots,u_{10}\);精排层把用户分成 \(v_1,\ldots,v_{10}\);一共n个用户,则有:
- \(u_1\cap u_j=\varnothing\)
- \(|u_i\cap v_j|=\frac n {100}\)
如何消除在评估召回层效果时,不同桶内受到不同精排层实验影响?
上面的第二点保证了召回层内的不同桶使用不同精排层策略的比例一致,因此不同实验桶内的区别仅存在于召回策略。
例如召回层分为两个桶A,B,而精排层也正交分为两个桶C,D(因两层分组策略是正交的保证A,B桶内C,D桶内的比例一致),则在A桶内的C,D用户的比例与B桶内的C,D用户一致。
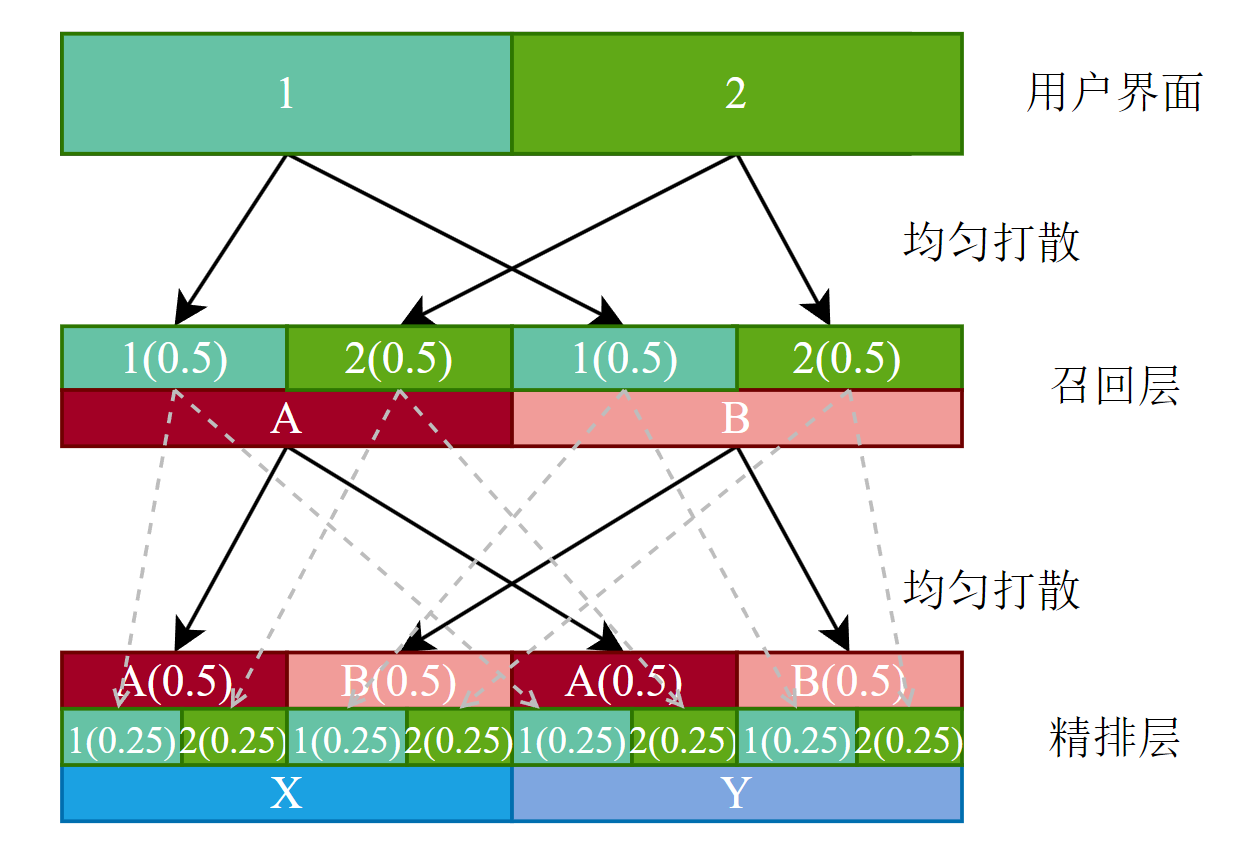
正因如此,将会导致两个结论:
- 召回层不同的实验桶仅存在召回策略的差异
- 召回层不同桶与Holdout桶的diff也仅来自于召回策略与其他层策略无关
4.2.1 正交
如果所有实验都正交,则可以同时做无数组实验。
- 同类的策略天然互斥,且它们的效果会相互增强1+1>2或相互抵消(1+1<2)
- 不同类型的策略通常不互相干扰1+1=2可作为互斥的两层
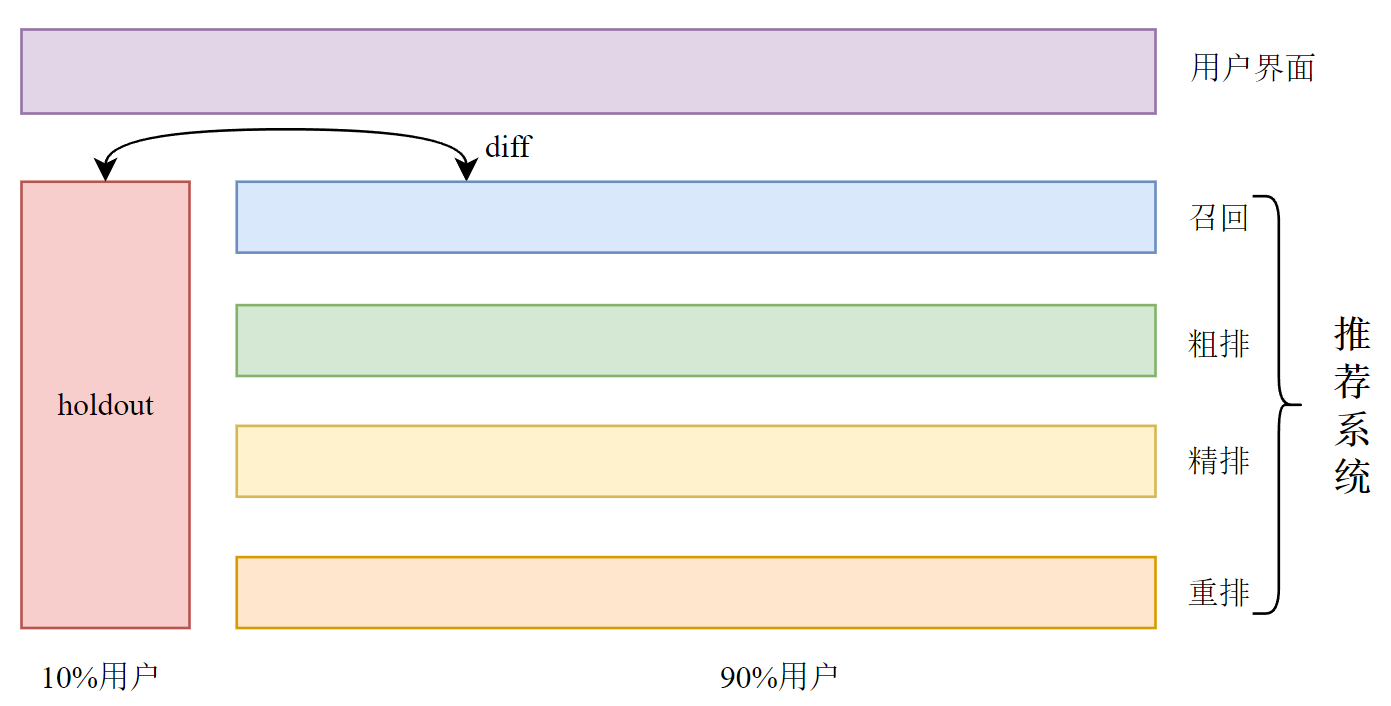
4.3 Holdout机制
- 每个实验独立汇报对业务指标的提升。
- 公司考察一个部门在一段时间内的业务指标、总体的提升。
- 取10%的用户作为holdout桶,推荐系统使用剩余的90%的用户做实验,两者互斥。
- 10%holdout桶 v.s. 90%实验桶的diff(需要归一化)为整个部门的业务指标收益
- 每个考核周期结束之后,消除Holdout桶,让推全实验从90%用户扩大到100%的用户。
- 重新随机划分用户,得到holdout桶和实验桶,开始下一轮考核期。
- 新的holdout桶与实验桶的各种业务指标的diff接近0。
- 随着召回、粗排、精排、重排实验推全,diff会逐渐扩大。
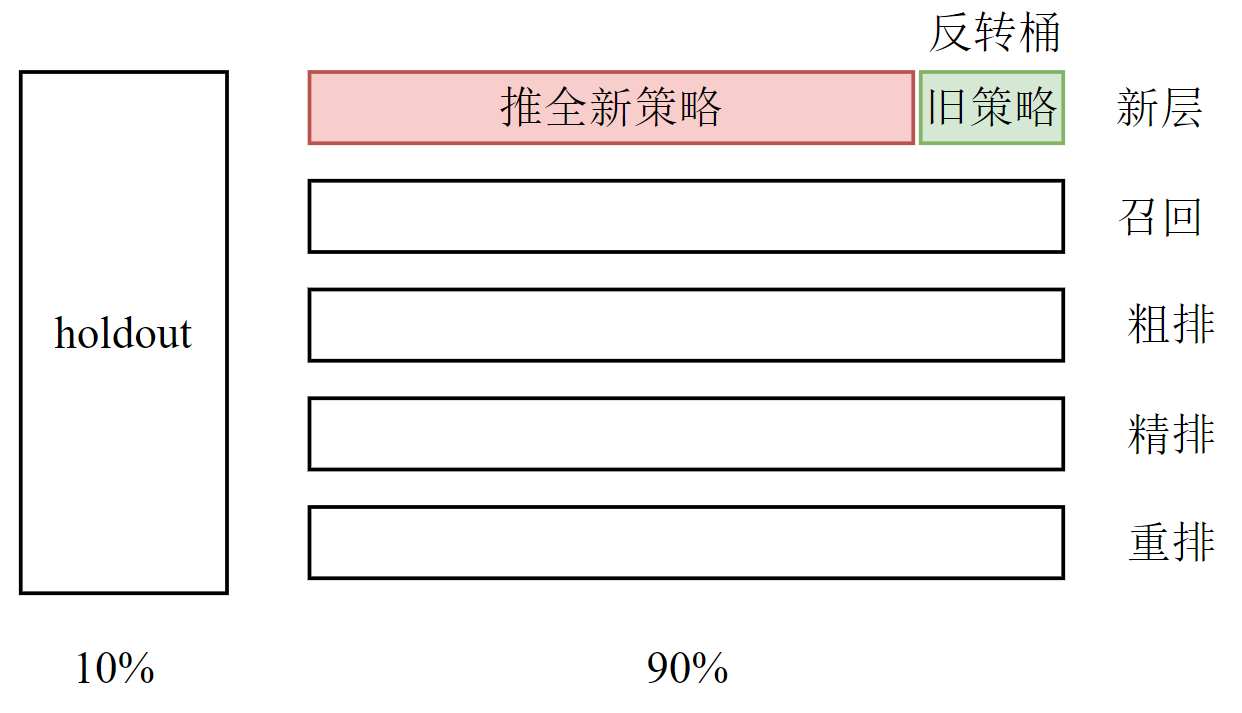
4.4 实验推全和反转推全
在完成小流量测试后便需要实验推全又或者反转推全。
4.4.1 推全实验

在验证新策略有效时便可进行推全,此时将会新增一层“新层”与其他层正交,用以验证在全样本的情况下小流量实验结果。
4.4.2 反转推全
有些指标(点击、交互)立刻会得到新策略的反馈,而有的指标却存在滞后性需长期观测,此时可用反转实验在推全的新层中开一个旧策略的桶,长期观察实验指标。