1 基于物品的协同过滤(ItemCF)
ItemCF召回的完整流程如下:
1.1 事先做离线计算
- 建立“用户➡️物品”的索引
-
记录每个用户点击、交互过的物品ID,给定任意用户ID,可以找到他最近感兴趣的物品列表。
- 建立“物品➡️物品”索引
-
计算物品之间两两相似度,对于每个物品索引与它最相似的k个物品。物品相似独的计算由如下公式确定:
\[ \text{sim}(i_1,i_2)=\frac{|w_1\cap w_2|}{\sqrt{|w_1|\cdot|w_2|}} \]
上式 \(w_1\)为喜欢物品 \(i_1\) 的用户集 \(w_1\),\(w_2\) 为喜欢物品 \(i_2\) 的用户集。
1.2 线上做召回
- 给定用户ID,通过“用户➡️物品”的索引,找到用户近期感兴趣的物品列表(last-n)。
- 对于last-n列表中的每个物品,通过“物品➡️物品”的索引,找到top-k相似的物品。
- 对于取回的最多nk个相似物品,用以下公式预估用户对物品的兴趣分数。 \[ R_{u,i}=R_{u,j}\cdot\text{sim}(i,j) \]
上式中的 \(j\) 表示物品i是由j召回的,\(R_{u,\cdot}\) 表示用户对某物品的兴趣分数。对于重复的物品,利用兴趣分相加进行去重。
- 返回分数最高的x个物品,作为推荐结果召回通道的输出。
ItemCF采用索引避免了枚举所有的物品,但在离线计算时计算量大,与之相对的是线上计算量小。其主要使用用户行为定义物品相似度。
2 Swing召回通道
Swing召回通道主要是为了解决小圈子问题。假设两篇不相关的物品(如某网络商品降价,某公司裁员)被同时推入一个微信群,导致大量用户同时点击这两篇文章,使得推荐系统认为两个物品相似,造成误判。为了解决这个问题可以对ItemCF算法中计算物品相似度公式进行如下改进:
\[ \text{sim}(i_1,i_2)=\sum_{u_1\in V}\sum_{u_2\in V}\frac{1}{\alpha+\text{overlap}(u_1,u_2)} \]
\(J_1\) 为用户 \(u_1\) 喜欢的物品集;\(J_2\) 为用户喜欢的物品集;\(w_1\) 为喜欢 \(i_1\) 的用户集;\(w_2\) 为喜欢物品 \(i_2\) 的用户集;\(V=w_1\cap w_2\);overlap(\(u_1,u_2\))=\(|J_1\cap J_2|\) 为用户重合度;\(\alpha\) 为超参。
- 二者仅在计算物品相似度有区别
- ItemCF认为只要两物品重合比例较高时,两物品便相似。
- Swing则在ItemCF的基础上额外考虑重合的用户是否来自一个圈子。
3 基于用户的协同过滤(UserCF)
采用UserCF的推荐系统将挖掘兴趣相似的网友,如下所示:
点击、点赞、收藏、转发笔记有较大重合的
关注的作者有较大重合的
UserCF的框架与ItemCF类似,其主要依靠用户相似度进行计算用户对每个物品的兴趣分数。
记用户之间的相似度为 \(\text{sim}(u_i,u_j)\);用户对物品I的兴趣为 \(\text{like}(u_i,I)\),则预估用户对候选物品的兴趣为 \(\sum_j \text{sim}(u_i,u_j)\cdot\text{like}(u_j,I)\)。用户间相似度的计算公式如下:
\[ \text{sim}(u_1,u_2)=\frac{|I|}{\sqrt{|J_1|\cdot|J_2|}} \]
上式中的 \(I=|J_1\cap J_2|\);\(J_1\) 表示用户 \(u_1\) 喜欢的物品集;\(J_2\) 表示用户 \(u_2\) 喜欢的物品集。为了降低物品热门度对用户相似度的影响,可采用如下改进:
\[ \text{sim}(u_1,u_2)=\sum_{l\in I}\frac{1}{\log(1+n_l)} \]
上式中的 \(n_l\) 表示物品的热门度。
基于用户的协同过滤算法的完整召回过程与ItemCF类似,其主要步骤如下:
3.1 离线计算
- 建立“用户➡️物品”的索引。(其中主要记录物品ID和用户对物品的兴趣分数)
- 建立“用户➡️用户”的索引。(记录用户ID和用户相似度)
示意图仅需将之前示意图颜色框中的物品换成用户。
3.2 线上召回
- 给定用户ID,通过“用户➡️用户”的索引找到top-k相似用户。
- 对于每个top-k相似用户,通过“用户➡️物品”的索引,找到用户近期感兴趣的物品列表(last-n)。
- 对于召回的nk个相似用户,用公式预估用户对每个物品的兴趣分数,
- 返回分数最高的100个物品,作为召回结果。
4 矩阵分解模型
5 双塔模型
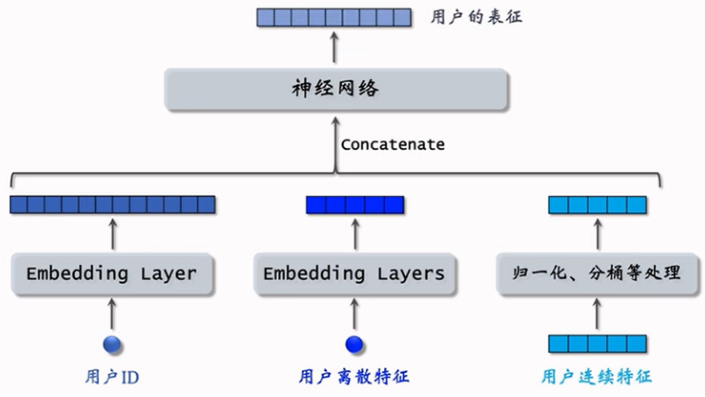
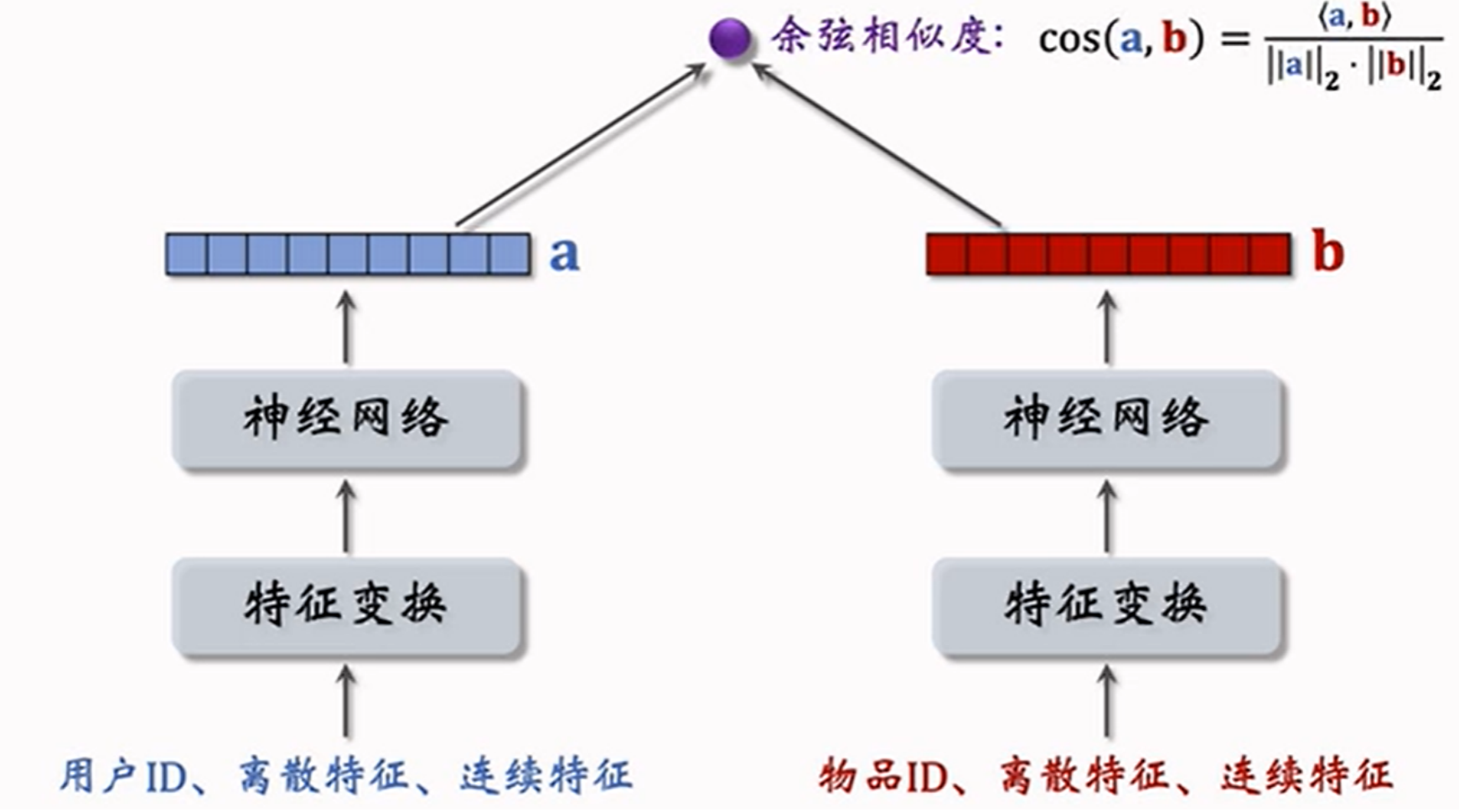
双塔模型较之前的召回通道包含了更多的用户信息,例如用户的离散和连续特征。
5.1 双塔模型结构
连续特征的处理得结合相关指标的实际含义和场景来进行。例如在点击预测率时用户的年龄、消费档次、购买深度都可以进行分桶处理,减少数据表示的复杂度。
- 不同离散特征均对应不同embedding层
- ⽤⼾连续特征要对数据进⾏归⼀化(如均值为0,标准差为1)、取log、分桶等处理
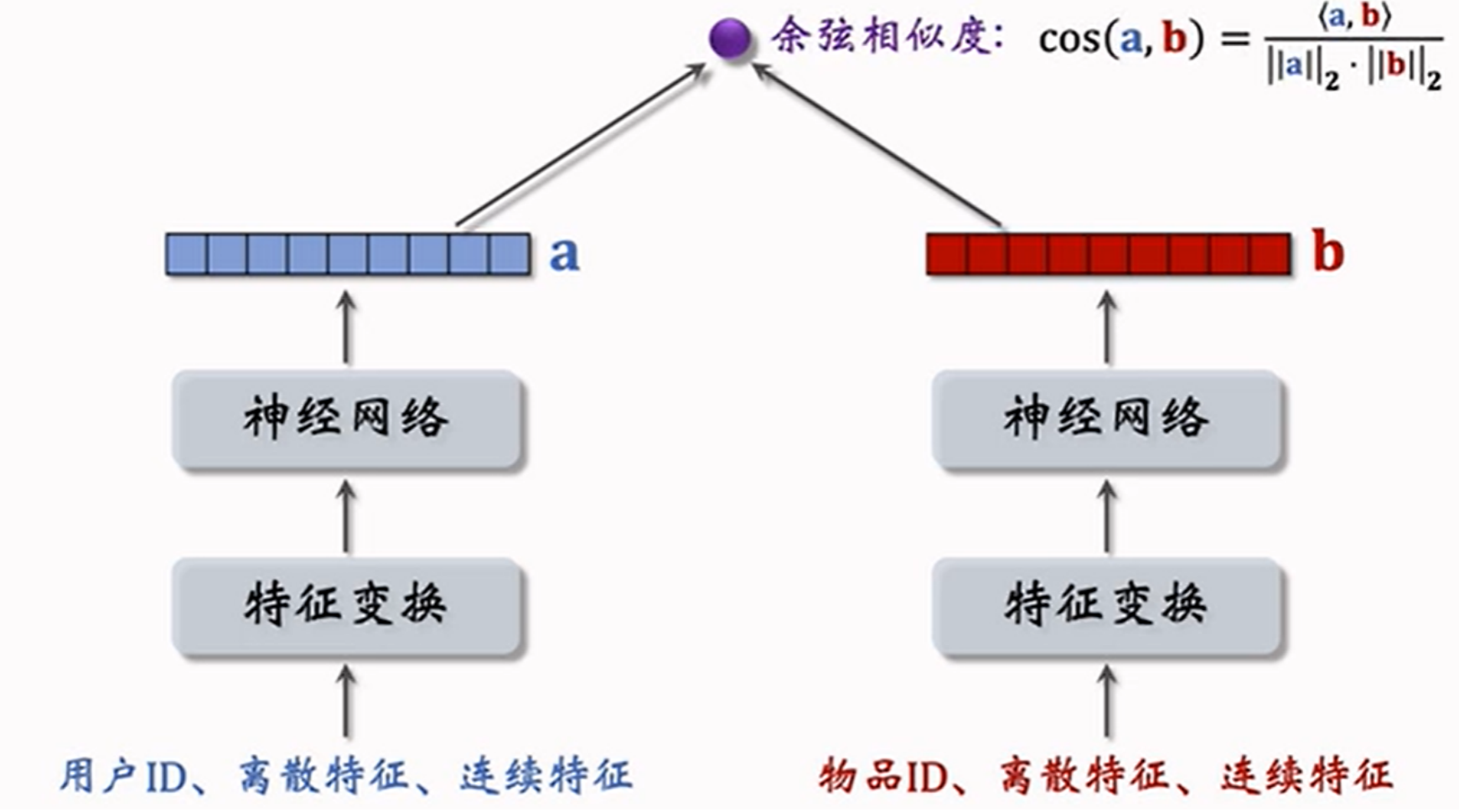
双塔模型左边的塔提取⽤⼾特征、右边的塔提取物品特征,⽤余弦相似度作为⽤⼾对物品的兴趣预估值:
5.2 双塔模型训练
目的:训练主要用于让模型学习到用户感兴趣的物品是啥,常用的方法如下:
- pointwise:独⽴看待每个正样本和负样本,做简单⼆元分类
- pairwise:每次取⼀个正样本,⼀个负样本
- listwise:每次取⼀个正样本,多个负样本
5.2.1 pointwise训练
是一种有监督的学习方式,利用(正样本, +1)和(负样本, -1)训练模型。
在实践中常常让正负样本数量的比例设置为 1:2 或 1:3。
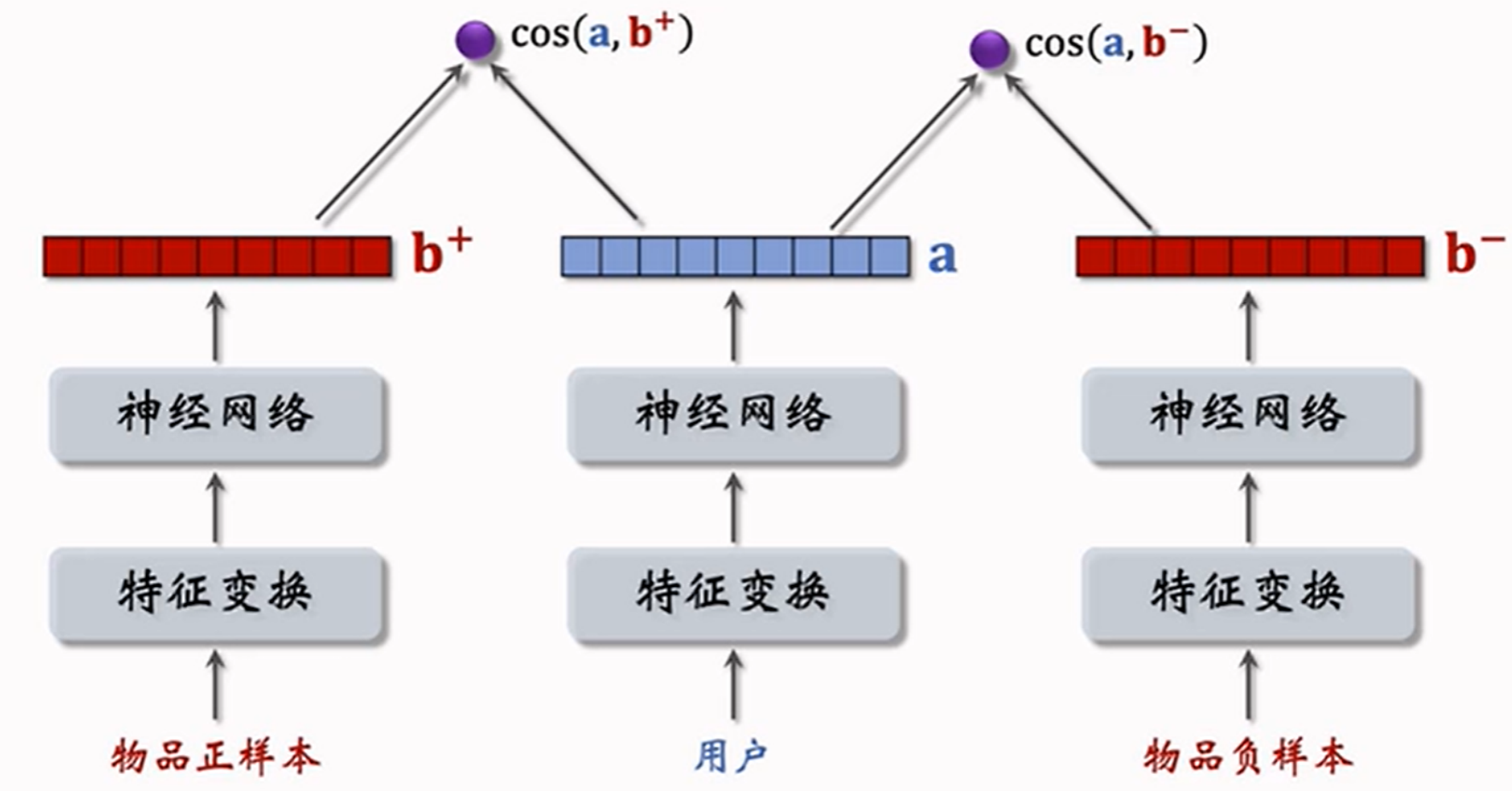
5.2.2 pairwise训练
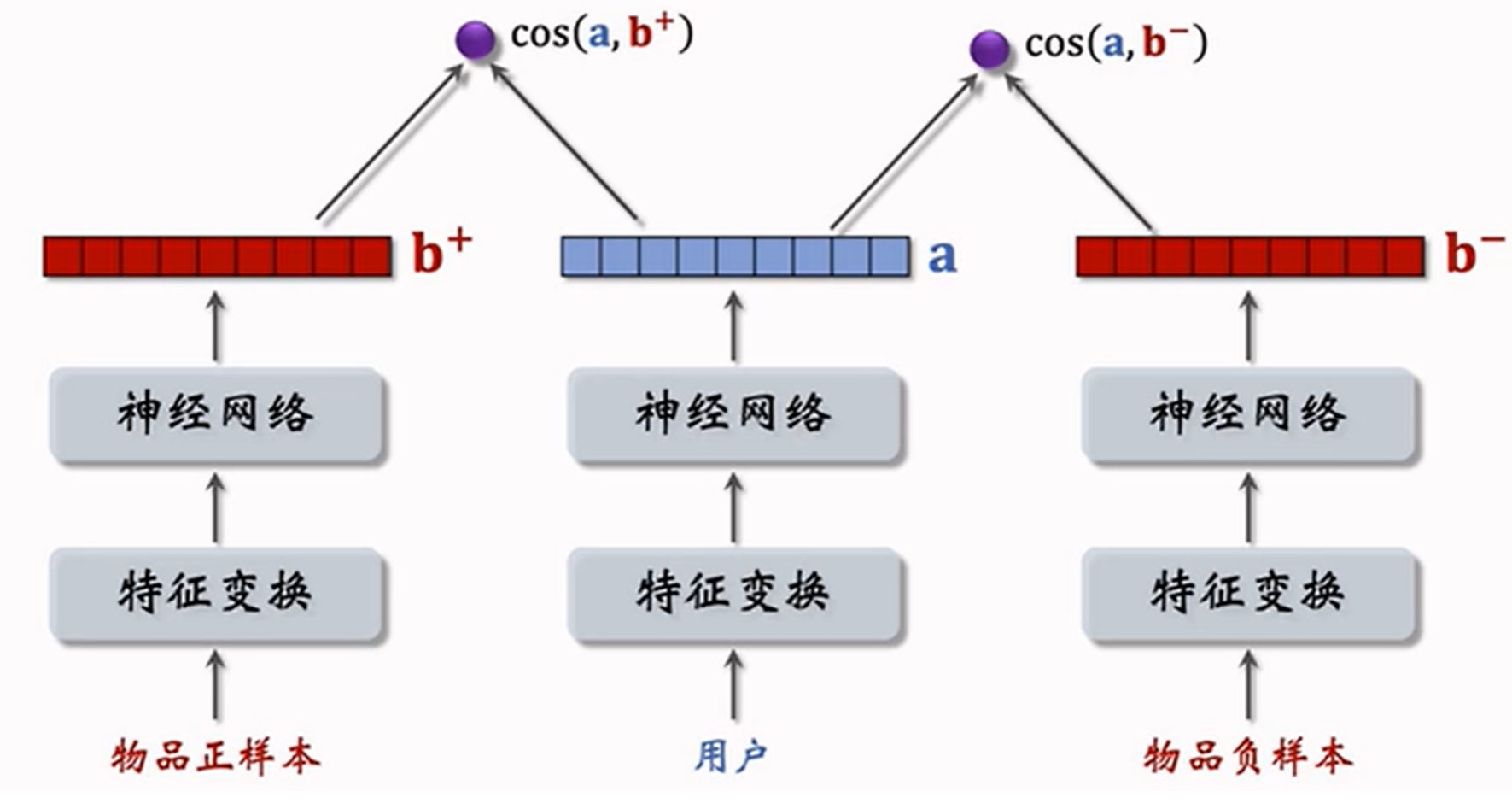
pairwise训练是⼀种⽆监督学习,利⽤(正样本, 负样本)训练模型。其主要⽬标是:鼓励 \(cos(a,i^+) > cos(a,i^-)\)。
即可理解为:
- 正样本的相似度大于负样本的相似度
- 正样本的相似度与负样本的相似度之差大于一个阈值 \(m\)
由此可得到如下损失函数:
\(L(a,i^+,i^-) = max(0, cos(a,i^+) - cos(a,i^-) + m)\) 使用梯度下降取优化双塔神经网络的参数
\(L(a,i^+,i^-) = \log(1 + e^{\sigma(cos(a,i^-) - cos(a,i^+))})\) 最小化该损失函数,可以使得正样本的相似度大于负样本的相似度,\(\sigma\) 是超参数。 ### listwise训练
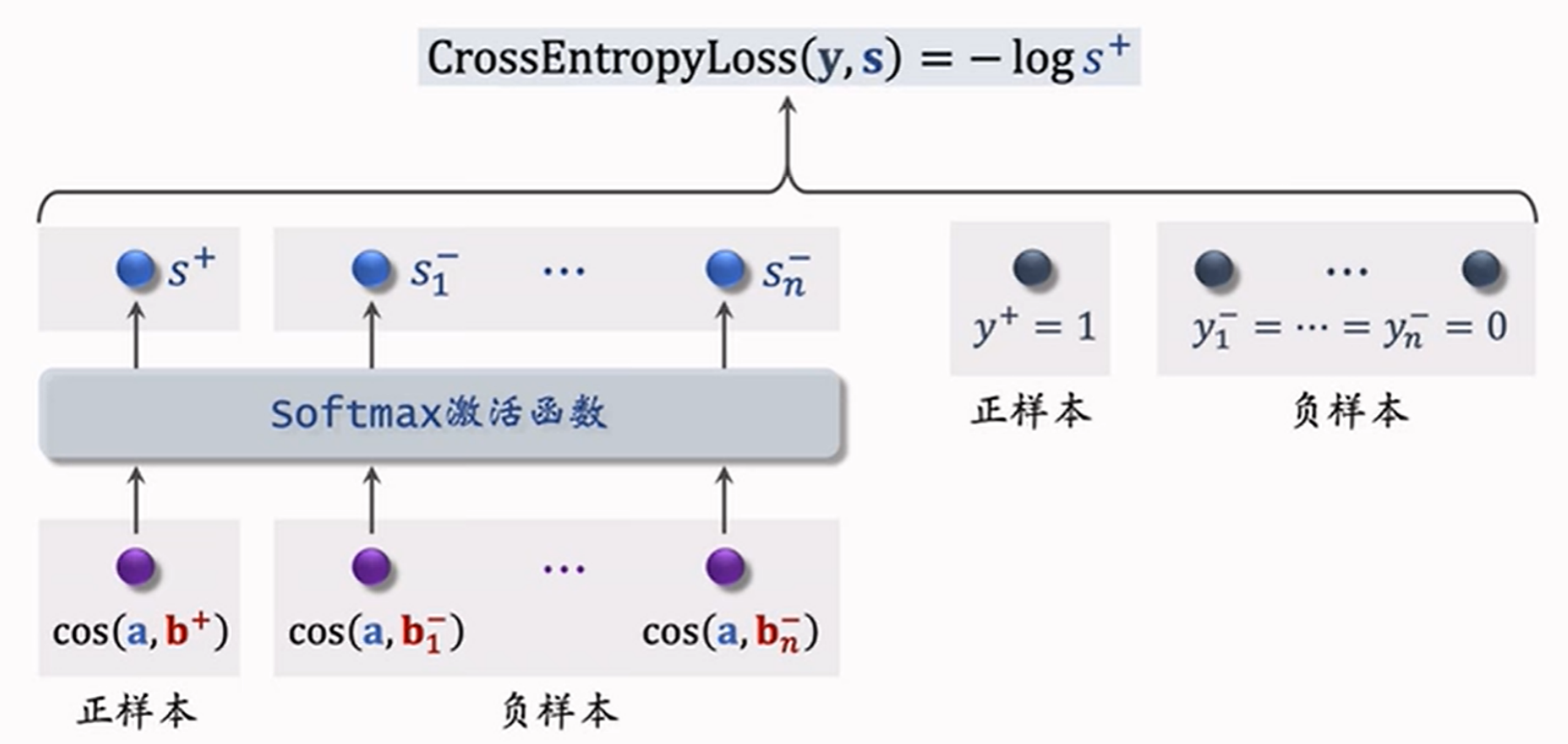
5.2.3 listwise训练
listwise训练是⼀种有监督学习,利⽤(正样本, 1)和多个(负样本, 0)训练模型。并采用交叉熵损失函数。
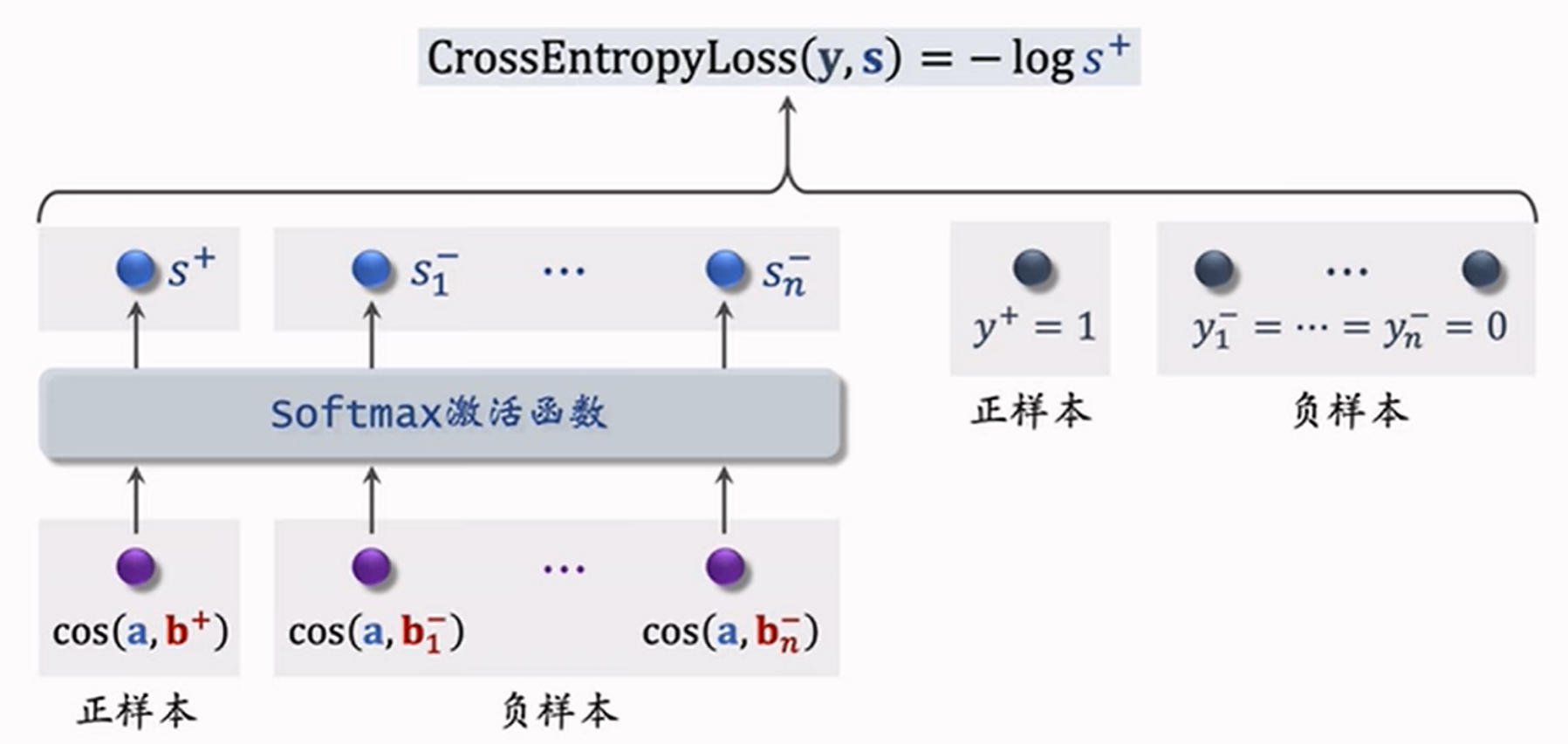
从点击数据中随机抽取1个⽤户的一个正样本和多个负样本组成⼀个batch,考虑下⾯损失函数:
\[ L = -\log \frac{\exp{(\cos(a,b_i)-\log p_i)}}{\sum_{j=1}^{n} \exp{(\cos(a,b_j)-\log p_j)}} \]
其中,\(p\) 是用于纠偏的项。
在双塔模型中,物品特征和用户特征在进入神经网络前并没有融合,这种情况称为后期融合,而在进入神经网络前便进行融合的模型称为前期融合,此时进入模型的参数过大,造成计算量过大不适合召回。前期融合的模型更适合排序。